
티스토리 뷰
목차
0. Abstract
1. Introduction
1.1 Goal of Research
1.2 Challenges in Instance Segmentation
1.3 Characteristics of Mask R-CNN Architecture
2. Mask R-CNN
2.1 Faster R-CNN
2.2 Mask R-CNN
2.3 Mask Representation
2.4 RoIAlign
2.5 Network Architecture
3. Experiments: Instance Segmentation
3.1 Main Results
3.2 Ablation Experiments
3.3 Bounding Box Detection Results
4. Mask R-CNN for human Pose Estimation
0. Abstract
본 논문에서는 object instance segmentation을 위한 간단하고 유연하고 일반적인 프레임워크를 제안한다. 제안한 방법은 이미지 안의 객체를 효율적으로 인식할 뿐만 아니라 높은 품질의 segmentation mask를 생성한다. 이는 Faster R-CNN에서 기존 bounding box recognition을 위한 branch와 평행하게 object mask를 예측할 수 있는 branch를 더한 형태이다. Mask R-CNN은 학습하기 쉽고 Faster R-CNN에 비해서 작은 overhead만 더해진다. 또한, 다른 task들에 일반화해서 적용하기 용이하다.
* Semenatic Segmentation vs Instance Segmentation

(1) Semantic Segmentation
Semantic Segmentation은 이미지의 모든 픽셀을 해당 class로 분류하는 것이 목적이다. 따라서, 동일한 클래스의 객체는 따로 분류하지 않고 그 자체가 어떤 클래스에 속하는지만 생각한다. 위 사진에서와 같이 세 마리의 양을 모두 Sheep라는 클래스로 분류하고, 같은 색으로 표현된다.
(2) Instance Segmentation
Instance Segmentation은 Semantic Segmentation과 목적은 유사하다. 그러나, Semantic Segmentation과 다르게 같은 클래스의 객체도 다른 label로 취급한다. 위 사진에서도 세 마리의 양을 모두 다른 객체로 인식해서 label을 붙여준 것을 확인할 수 있다.
1. Introduction
1.1 Goal of Research
최근 vision community에서는 object detection과 semantic segmentation이 짧은 시간 안에 매우 빠른 발전이 있었다. 이것이 가능할 수 있었던 이유는 Fast/Faster RCNN과 FCN과 같은 강력한 baseline system 덕분이었다. 따라서, 본 논문에서의 목표는 instance segmentation에서 이러한 역할을 하는 프레임워크를 만드는 것이다.
1.2 Challenges in Instance Segmentation
Instance segmentation이 어려운 이유는 객체에 대한 정확한 detection이 이루어져야 하면서도 instance를 정밀하게 segment해야 하기 때문이다.
Instance Segmentation = Object Detection + Semantic Segmentation
이로 인해서 instance segmentation에서 좋은 성능을 내기 위해서는 매우 복잡한 method가 필요하다고 생각할 수 있다. 그러나, 본 논문은 기존의 instance segmentation의 state-of-the-arts를 능가할 수 있는 놀라울정도로 간단하고, 유연하고 빠른 시스템을 제안하고 있다.
1.3 Characteristics of Mask R-CNN Architecture

Mask R-CNN은 Faster R-CNN에서 classfication과 bounding box regression을 하는 branch와 평행하게 각 RoI(Region of Interest)의 segmentation mask를 예측할 수 있는 branch를 추가한 것이다. Mask branch는 각 RoI에 추가된 작은 FCN으로 각 pixel의 segmentation mask를 예측한다. Mask R-CNN은 Faster R-CNN을 기반으로 학습시키면 되기 때문에 적용하기에 간단하고 유연하게 많은 아키텍처 디자인에 적용할 수 있다. 또한, mask branch는 작은 computational overhead만 더하기 때문에 시스템이 빠르고 실험을 빠르게 할 수 있다.
Mask R-CNN이 좋은 성능을 내기 위해서는 mask branch를 적절하게 구축하는 것이 중요하다.
(1) RoIAlign 방식 이용
Faster R-CNN은 object detection을 위한 모델로 input과 output 사이의 pixel-to-pixel alignment을 위해서 제작되지 않았다. 따라서, Mask R-CNN은 이를 해결하기 위해서 RoIPool 대신 spatial location을 보존할 수 있는 RoIAlign 방식을 이용한다. RoIAlign을 이용한 결과 mask의 정확도가 증가하였다.
(2) Mask와 class 예측 과정 분리
각 클래스에 대해서 binary mask를 독립적으로 예측하는 것이 중요하다. FCN의 경우는 per-pixel multi-class categorization을 하여서 segmentation과 classfication 과정을 연관시키는데, 이를 본 논문에서의 instance segmentation에 적용시키면 낮은 성능을 보인다.
* 추가 설명

기존 모델들의 경우 mask와 class prediction을 동시에 수행했다. 하나의 픽셀에 대해서 softmax를 취해 각각의 클래스들의 확률을 계산하고 multinomial cross entropy loss를 이용해 학습한다. 예를 들면 특정 픽셀에 대한 클래스가 5개이면 softmax를 취해서 [0.1, 0.25, 0.15, 0.2, 0.3]와 같이 확률을 계산한 뒤에 이 중 가장 큰 값을 가지는 class를 정답으로 예측한다.
그러나 본 논문에서는 mask와 class의 prediction을 분리하였다. 각 class별로 binary mask를 생성한 후에 픽셀이 해당 class에 해당하는지 여부를 판별한다. 따라서, mask에 대한 loss는 binary cross entropy loss로 정의된다.
2. Mask R-CNN
Mask R-CNN은 개념적으로 간단하다. Faster R-CNN이 하나의 candidate object에 대해서 class label과 bounding-box offset의 두 가지 output을 낸다면 이에 세 번째 branch를 더해서 object mask를 출력하게 된다. 또한, class와 box output과는 별개의 output을 내기 때문에 객체에 대해서 더 세밀한 spatial layout을 필요로 한다.
2.1 Faster R-CNN

Faster R-CNN은 two-stage로 구성되어 있다.
(1) Region Proposal Network(RPN)
RPN은 이미지에서 후보 bounding box들을 제안하는 단계이다.
(2) RoIPool로부터 feature 추출
각 후보 box에 대해서 RoIPool을 이용해서 feature를 추출하고, classfication과 bounding-box regression을 수행한다.
2.2 Mask R-CNN
(1) Structure
Mask R-CNN도 two-stage로 구성되어 있다. 이는 Fast R-CNN에서 bounding box classfication과 regression을 평행하게 구성한 구조에서 영감을 받았다. 이러한 방식은 기존 multi-stage pipeline을 매우 단순화시켜 준다.
* R-CNN vs Fast/er R-CNN vs Mask R-CNN

1) Region Proposal Network(RPN)
2) 각 Roi에 대한 binary mask 구하기
Class와 box offset을 예측하는 것과 평행하게 Mask R-CNN은 각 RoI에 대한 binary mask를 예측한다. 이는 classfication이 mask 예측에 의존하는 최근 많은 시스템과 대조된다.
(2) Loss Function

위와 같이 각 sampled RoI에 multi-task loss를 정의한다. L_{cls}와 L_{box}는 Faster R-CNN과 동일한 loss를 사용하다. Mask branch는 각 RoI의 output에 대해서 해상도가 m * m인 K개의 binary mask를 encode하여서 Km^2 차원을 가진다. L_{mask}는 average binary cross-entropy loss로 정의한다. Mask R-CNN에서는 mask와 class에 대한 예측이 독립적으로 이루어지기 때문에 연산량이 줄어들고 성능이 좋아진다. Per-pixel softmax와 multinomial cross-entropy loss를 이용하는 FCN과 달리 Mask R-CNN은 per-pixel sigmoid와 binary loss를 이용한다.
* Faster R-CNN Loss Function

L_{cls} : Cross Entropy Loss
L_{loc} : Smooth L1 Loss
식에서 L_{loc} 앞에 있는 부등호는 u=0, 즉 background class인 경우에 regression loss를 반영하지 않겠다는 의미이다. 이는 Region proposal 중 객체가 아닌 경우에는 학습에서 제외하기 위함이다.

위 식은 smooth L1 loss에 대한 수식이다.
2.3 Mask Representation
Mask는 input object의 spatial layout를 encode한다. 이때 fully-connected layer를 통하면서 불가피하게 짧은 output vector로 나오는 class label이나 box offset와 달리 convolution의 pixel-to-pixel correspondence에 의해서 mask의 spatial structure를 추출할 수 있다. Mask R-CNN은 각 RoI로부터 FCN을 이용해서 m * m mask를 예측한다. 이는 각 layer의 mask branch가 객체의 m * m spatial layout을 유지할 수 있도록 해준다. 이전 fc layer를 이용해서 mask 예측을 하는 이전 방식들과 달리 본 논문에서 제시하는 방식은 파라미터 개수도 더 적게 필요하고, 더 정확한 예측을 하게 해준다.
2.4 RoI Align
(1) RoIPool

- RoIPool은 각 RoI에서 작은 feature map을 추출하기 위한 standard operation
- 절차
- 1) floating-number RoI를 discrete하게 quantize를 시켜줌
- 2) 1)에서 quantized된 RoI는 spatial bin으로 나눠지고, 각 spatial bin에 대해서 quantize가 이루어짐
- 3) 각 bin을 이루는 feature value가 aggregate됨(주로 maxpooling 이용)
- Quantization을 하면 입력 이미지의 원본 위치 정보가 왜곡되기 때문에 classfication task에서는 문제가 발생하지 않지만, pixel-accurate mask를 예측하는 segmentation task에서는 문제 발생
* Quantization
- 실수값을 정수로 제한하는 방식
- 위 사진에서 145 * 200 사이즈의 RoI를 32로 나눠서 scaling해주면 소수점이 나오기 때문에 quantization을 거쳐서 소수점을 반올림해준다. 이를 통해서 4 * 6 크기의 feature map을 얻는다.
(2) RoIAlign

- RoI boundary나 bin에 quantization을 피함, 추출된 feature를 입력을 이용해서 적절하게 align시킴 → bilinear interpolation 이용
- 절차
- 1) RoI projection을 통해 얻은 feature map을 quantization 없이 그대로 사용
- 2) Bilinear Interpolation을 이용해서 RoI bin의 4개의 sampling point 값 추정
- 3) 하나의 RoI bin에 있는 sampling point를 aggregate 시킴
- RoIWarp와 RoIPool과 비교했을 때도 RoIAlign이 좋은 성능을 보임
* Bilinear Interpolation

Bilinear interpolation은 2차원 좌표 상에서 두 좌표가 주어져 있을 때 중간에 있는 값을 추정하는 방법이다. 구하는 식은 아래와 같다. 이때 Q는 추정하려는 sampling point의 4개의 인접한 셀의 값이고, x, y는 추정하려는 sampling point의 좌표, x_1, y_1, x_2, y_2는 인접한 4개의 셀의 좌표 값이다.
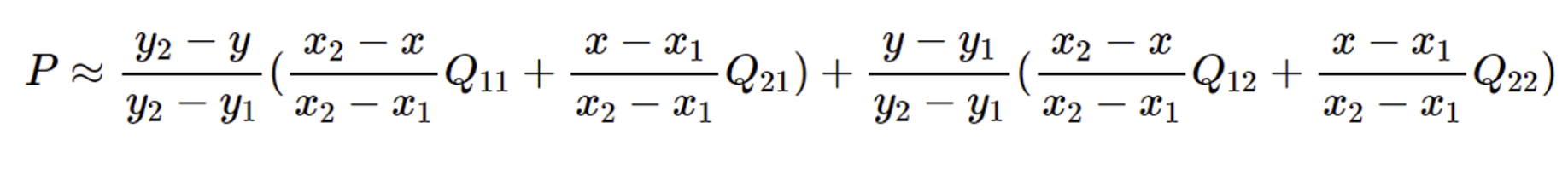
2.5 Network Architecture
(1) Backbone

- 이미지에서 feature 추출을 위한 아키텍처
- 50이나 101 layer 깊이를 가지고 있는 ResNet과 ResNeXt과 FPN(Feature Pyramid Network)을 backbone으로 사용
- C4 : 4번째 stage의 최종 convolution layer의 추출된 feature를 이용한 ResNet으로 구성된 Faster R-CNN
- FPN : scale에 따라서 feature pyramid의 다른 레벨로부터 RoI feature 추출

(2) Head
- 각 RoI에 대해 bounding-box recognition(classfication, regression)과 mask prediction을 위한 아키텍처
- 기존 Faster R-CNN의 head에 추가적인 fully convolutional mask prediction branch 추가
- backbone에 따라 head의 구조가 달라짐
3. Experiments: Instance Segmentation
Mask R-CNN과 기존 state of the art 네트워크들과 비교해보았다.
3.1 Main Results


위 표에서 볼 수 있듯이 COCO 2015, 2016 segmentation challenge에서 수상한 MN와 FCIS의 성능을 뛰어넘은 것을 볼 수 있다. ResNet-101-FPN을 backbone으로 하는 Mask R=CNN은 FCN은 FCIS+++보다 훨씬 우수한 성능을 보였다.

위 사진은 Mask R-CNN baseline과 FCIS+++를 적용시킨 결과이다. FCIS+++는 overlapping되는 객체들이 보이는 반면, Mask R-CNN는 instance segmentation이 잘 이루어진 것을 볼 수 있다.
3.2 Ablation Experiments

(a) Architecture
- 네트워크 깊이가 깊을수록 좋은 성능을 보임
- FPN이 C4보다 좋은 성능을 보임
- ResNeXt가 ResNet의 성능을 향상시킴
(b) Multinomial vs Independent Mask
- Multinomial mask보다 per-class binary mask를 이용하는 것이 더 좋은 성능을 보임
(c) Class Specific vs Class-Agnostic Mask
(d) RoIAlign
- RoIAlign을 이용하는 것이 좋은 성능을 보임
(e) Mask Branch
- MLP(multi-layer perceptron)과 FCN(fully convolutional network)를 비교해본 결과 FCN을 사용하는 것이 spatial layout을 확실하게 encoding하는데 강점을 보임
3.3 Bounding Box Detection Results

Mask output은 무시하고 Mask R-CNN을 기존 state-of-the-art COCO bounding-box object detection과 비교해본 결과 ResNet-101-FPN을 backbone으로 사용한 Mask R-CNN의 성능이 높게 나왔다.
또한, mask branch를 제외하고 Mask R-CNN을 학습한 결과(Faster R-CNN, RoIAlign) Mask R-CNN보다는 낮은 성능을 보였지만, 다른 Faster R-CNN 보다는 RoIAlign으로 인해 좋은 성능을 보였다. 이는 multi-task training에 의해 나온 결과라고 볼 수 있다.
4. Mask R-CNN for Human Pose Estimation
Mask R-CNN은 다른 task들에 일반화하기 쉽기 때문에 human pose estimation task에도 확장할 수 있다. 각 keypoint’s location에 대해서 one-hot mask를 적용시켜서 각 K개의 keypoint tyes에 대해서 K개의 mask를 예측하는데 Mask R-CNN을 적용한다. 객체의 각 K개의 keypoint에 대해서 one-hot m * m binary mask를 학습시키는데 이때 오직 한 개의 픽셀만이 foreground이다. 해당 실험은 Mask R-CNN 프레임워크의 일반성을 입증하기 위한 것이기 때문에 human pose에 대한 최소한의 domain 지식이 활용된다.

참고 자료
https://computer-on-gyul.tistory.com/entry/논문-리뷰-Mask-R-CNN-ICCV-2017
https://velog.io/@kimkj38/논문-리뷰-Mask-R-CNN
https://velog.io/@sksmslhy/Paper-Review-Mask-R-CNN
https://oi.readthedocs.io/en/latest/computer_vision/object_detection/fast_r-cnn.html
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] U-Net: Convolutional Networks for Biomedical Image Segmentation (0) | 2023.09.22 |
|---|---|
| [논문 리뷰] Deep Residual Learning for Image Recognition (0) | 2023.09.14 |